Comparison of SK1 data and SK1 MC (for likelihood variables)
In order to make sure that the variables that are being used in the Likelihood study make sense. I compared each of the variables between data and MC using the SK-I atmospheric dataset/MC.
Of course, only the variables that do not require to know the true direction of the neutrino are compared here.
070110
In all previous plots, I used Nakayama's MC. Just as a checked I reapplied polfit2 to 9 MC files.
Now they agree, so the problem comes probably from a different version
of polfit between Nakayama-san and me. The question is: who is right??
Here are the plots comapring my polfit2 to data, you can see real difference in Diff likelihood and pi0_e(1,1):
dlfct
probms
pi0 mass
pi0_e(2,1)
and energy fraction
070109
Just updated a few plots:
for the difference of likelihood:
with polfit2 (see the big difference at high energies)
without polfit2 (good agreement)
070108
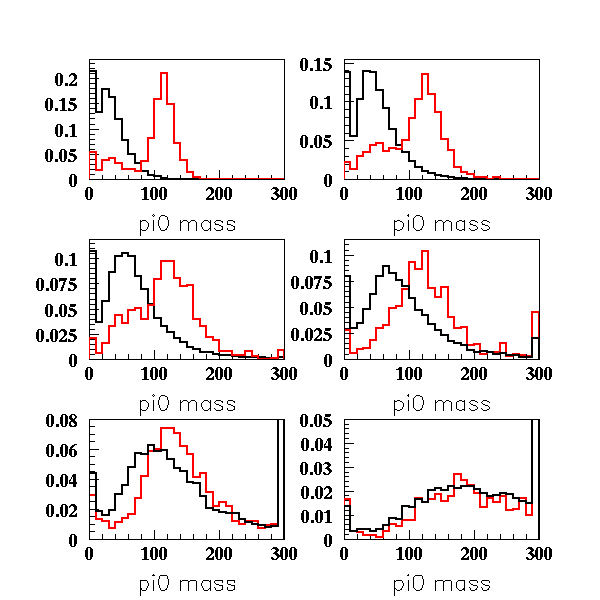
Most of the variables looked fine as you can see on the following plots:
Those plots are split in energy bins (0-350MeV/ 350-850MeV/850-1500MeV/ above 1500MeV)
black = sk1data with polfit2, red = MC with polfit2
(NB: the events are fully contained, inside FV, 1ring, elike, no decay electron)
dlfct
probms
pi0 mass
pi0_e(2,1) , pi0_e(1,1) and energy fraction
But the difference between the 2 likelihood given by polfit (pi0like(1)-pi0like(2)) is significantly different at high energy as you can see in the following plots:
All energies together
Split by energy
Split by energy (zoomed)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}